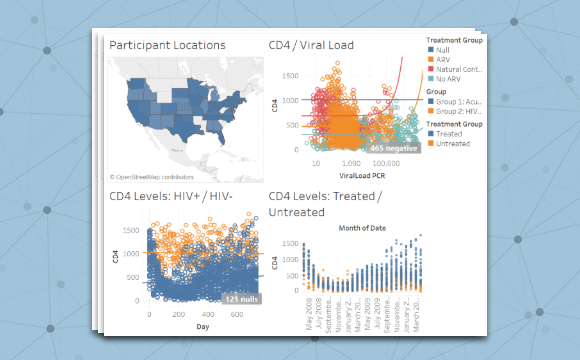
More than a tool to facilitate data integration and analyses, LabKey has partnered with Tableau to help research teams visually communicate their findings and build consensus with stakeholders. After all, the most important scientific discovery can’t change the world unless it can get your attention. Key insights gleaned from complex biomedical research data can be overwhelming to explain and even more difficult for some audiences to understand. Insightful and beautiful visualizations created in Tableau from data within LabKey Server can help bring complex data to life, and clearly communicate key results.
Seamless Integration of LabKey Data with Tableau
LabKey integrates scientific data with a wide variety of external analysis and presentation tools, including Tableau Desktop. Gone is the need to hand over research data to visual designers who may not understand the science. The LabKey integration with Tableau allows you to make compelling charts and plots with tools designed for analysis. With Tableau and LabKey together, you can easily create compelling graphs, tables and other visual izations from your own research data. Presentations can be “live” so they automatically update when additional data is incorporated, or if you prefer, your research data visualizations can reflect a static snapshot.
izations from your own research data. Presentations can be “live” so they automatically update when additional data is incorporated, or if you prefer, your research data visualizations can reflect a static snapshot.
Tableau Technology Partner
As a Tableau Technology Partner, LabKey adds the ability to connect biomedical research data to the analytics and visualizations available with Tableau. Drag and drop the data you want, customize colors, styles, and layouts, and never pause or lose the integrity of your ongoing research. Tableau partners with leading technology companies in the data and analytics industry to seamlessly integrate with Tableau so people can collect, store, transform and connect to the data that is important to them.
Video: Using Tableau to Visualize Data in LabKey Server
Read more here:
https://www.labkey.org/wiki/Documentation/page.view?name=tableau


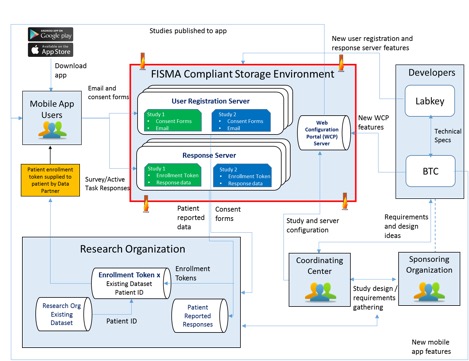

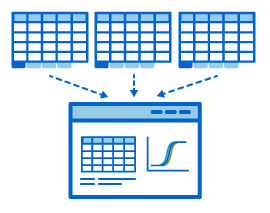 Providing support for multi-tabular excel output files and converting them into easy-to-read grids
Providing support for multi-tabular excel output files and converting them into easy-to-read grids LabKey Server’s Luminex data management tools help labs improve quality control of their data by:
LabKey Server’s Luminex data management tools help labs improve quality control of their data by: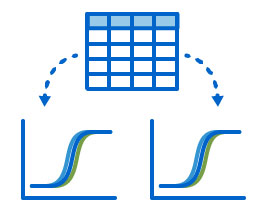 Logging changes to data records and allowing scientists to view the history of data transformations from the raw file to the analyzed results
Logging changes to data records and allowing scientists to view the history of data transformations from the raw file to the analyzed results
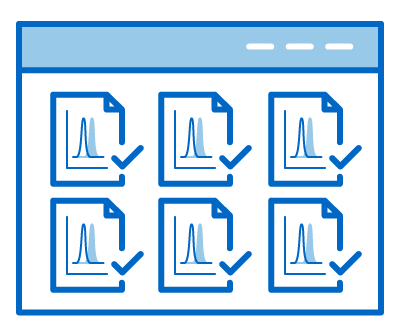

 1. Minimizing Data Redundancy of Research Efforts
1. Minimizing Data Redundancy of Research Efforts 2. Drawing More Reliable Conclusions from More Data
2. Drawing More Reliable Conclusions from More Data 3. Inspiring Novel Questions from Different Approaches
3. Inspiring Novel Questions from Different Approaches
 Manual file management relies on the individual contributor’s abilities to consistently create, name, and store data files. This opens the door to a wide range of human errors that will ultimately impact the discoverability and reliability of your data. Common consistency errors that result from manual data management include:
Manual file management relies on the individual contributor’s abilities to consistently create, name, and store data files. This opens the door to a wide range of human errors that will ultimately impact the discoverability and reliability of your data. Common consistency errors that result from manual data management include: