
A standard nomenclature is incredibly valuable for teams using LabKey Server to do collaborative biomedical research and becomes increasingly more important as they grow in size and data volume. Defining how data fields should be named is essential to the efficiency of teams, as it aids both those generating and/or capturing data as well as those conducting data analysis.
As you get started using LabKey Server, keep in mind the best practices below for defining and maintaining a standard nomenclature in your lab:
 Define Nomenclature Up Front
Define Nomenclature Up Front
Standardizing nomenclature may seem like an unnecessary up-front investment, but ultimately your team will experience less confusion and more efficiency as they progress with their work. Empower your team by allowing them to have a voice as you define which terms will be used in your research. By including team members in the process, they will feel more invested and be more likely to adhere to standard naming conventions.
Use LabKey QC Features to Ensure Consistency
In an ideal world, all team members will consistently use the nomenclature agreed upon by the team when adding data to your LabKey Server. But in practical application, it is more likely that from time to time a team member will mistakenly enter “H20” instead of the lab standard name “Water” into their ingredient list, potentially breaking standard reports, grid views, etc.
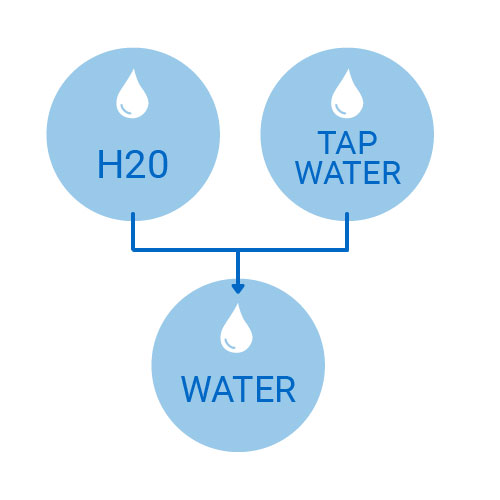
Using LabKey quality control features like lookups, aliases, and validators in key fields can help combat this scenario. A LabKey lookup will allow you to to map several common variations of a term to a desired standard field value. For example, an administrator could configure a lookup so that “H20” and “Tap Water,” common deviations from the standard, would both map to “Water.” These types of lookups allow teams to maintain the integrity of their data, in spite of inevitable human error.
Administrators can also use to regex or range validators on new data being entered to ensure that users are entering valid data into the system. By placing these restrictions, teams can improve data entry and help analyses down the pipeline.
 Evaluate and Adjust
Evaluate and Adjust
It’s easy to enforce the use of standard nomenclature when your team is small and your research is in its early stages. But over time, as teams grow and become further removed from when nomenclature guidelines were established, they can develop a “laboratory shift” in how things are named. In order to stay on top of your terminology and keep your data clean, plan to regularly review and assess your standard nomenclature. Are there additional terms that need to be defined? Have any standard terms become outdated? Are certain terms consistently being used incorrectly? Making small adjustments as your research needs evolve will help maintain the integrity of your data.




 Consistent Batch Preparation
Consistent Batch Preparation Following the Media Trail
Following the Media Trail
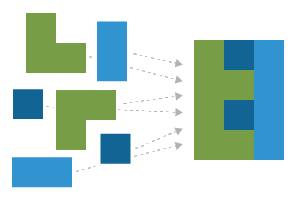 Integrating Heterogeneous Immunotherapy Data
Integrating Heterogeneous Immunotherapy Data
 Sharing reports and data with collaborators improves research, innovation, and ultimately subject care. Maintaining compliance and having the ability to quickly share data and reports is an important topic to tackle in immunotherapy research where subject safety and care is the top priority.
Sharing reports and data with collaborators improves research, innovation, and ultimately subject care. Maintaining compliance and having the ability to quickly share data and reports is an important topic to tackle in immunotherapy research where subject safety and care is the top priority.
 1. Define User Groups
1. Define User Groups 2. Consider Folder Structure
2. Consider Folder Structure 3. Monitor and Adjust
3. Monitor and Adjust
 The focus of pharmaceutical and biotech research has seen a significant shift in recent years. Many research teams are no longer driving towards building small molecules, but are instead focused on designing new protein-based therapeutics. Protein engineers at these organizations are often responsible for the structural design of target molecules as well as the experimental protein production and characterization of their designs.
The focus of pharmaceutical and biotech research has seen a significant shift in recent years. Many research teams are no longer driving towards building small molecules, but are instead focused on designing new protein-based therapeutics. Protein engineers at these organizations are often responsible for the structural design of target molecules as well as the experimental protein production and characterization of their designs.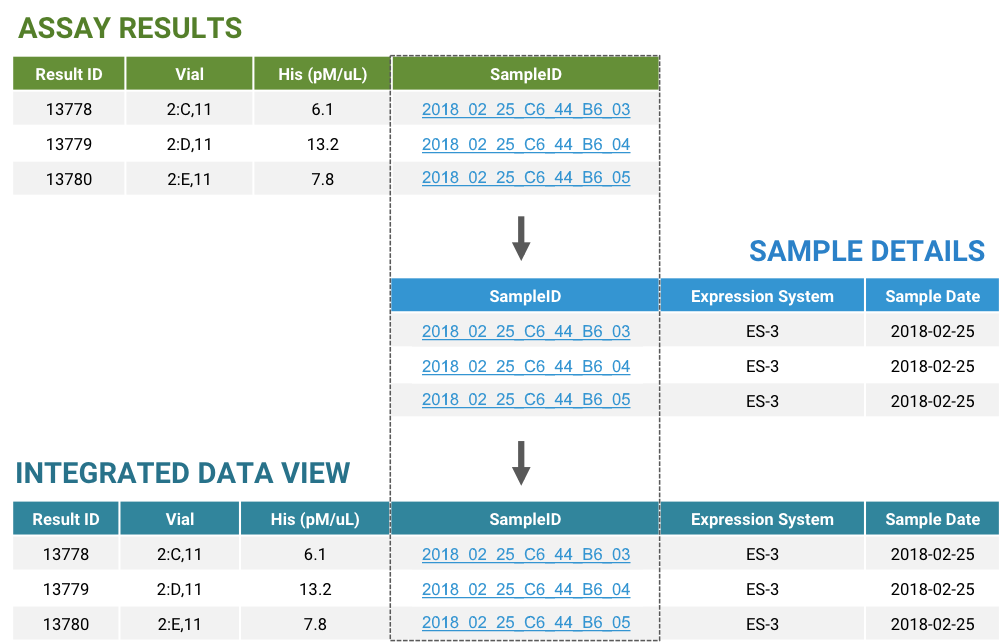


 Establishing Good QC Metrics
Establishing Good QC Metrics Collaborative Data Sharing
Collaborative Data Sharing
 1. Minimizing Data Redundancy of Research Efforts
1. Minimizing Data Redundancy of Research Efforts 2. Drawing More Reliable Conclusions from More Data
2. Drawing More Reliable Conclusions from More Data 3. Inspiring Novel Questions from Different Approaches
3. Inspiring Novel Questions from Different Approaches
 Manual file management relies on the individual contributor’s abilities to consistently create, name, and store data files. This opens the door to a wide range of human errors that will ultimately impact the discoverability and reliability of your data. Common consistency errors that result from manual data management include:
Manual file management relies on the individual contributor’s abilities to consistently create, name, and store data files. This opens the door to a wide range of human errors that will ultimately impact the discoverability and reliability of your data. Common consistency errors that result from manual data management include: