The LabKey Server platform can be easily configured to manage longitudinal study data allowing for efficient curation, analysis and publishing. These features include data integration, a customizable study framework, quality control workflows, an intuitive visualization builder, manuscript development tools, and de-identified data publishing.
The LabKey Server platform can be easily configured to manage longitudinal study data allowing for efficient curation, analysis and publishing. These features include data integration, a customizable study framework, quality control workflows, an intuitive visualization builder, manuscript development tools, and de-identified data publishing.
To help users configure LabKey server to their study data needs as well as to help those evaluating LabKey, we have put together a series of tutorials. You can also try LabKey server using these resources:
>Explore an Example Research Study
>Start a Trial of LabKey Server
Research Studies with LabKey Server
Interactive Data Grids
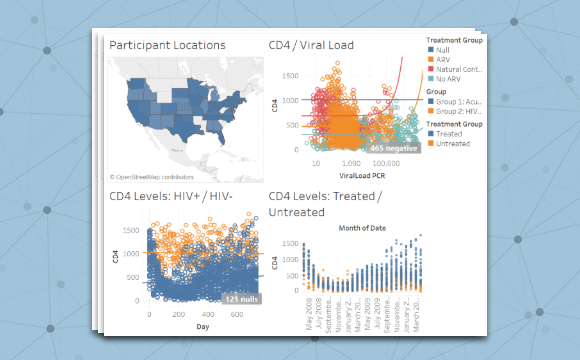
The LabKey platform provides a graphical user interface to import, query and analyze your research data. Learn how easy it is to chart, correlate, and drill down into your data in this quick online tour.
Time Chart Visualizations
Visually presenting research data in a way that your users can easily answer their own questions can bring your results to life. In a LabKey time chart, the user can change how the underlying data is shown while the live underlying data updates continuously behind the scenes. In this visualization you can experiment by checking the grouping boxes of the time chart. If you click ‘Edit’ and then ‘Chart Type’ you can access the Plot and Chart Builder to see other data in other ways.
Plot and Chart Builder
In the common plot editor, you can change the type and layout of a chart. On this example, click ‘Chart Type’ to select another plot type, change what data is shown using drag and drop, and use color and shape to add more information. To learn more about building meaningful visualizations within a study see this tutorial- Tutorial: Longitudinal Studies
Quality Control
Tracking the quality of data involves various control measures. LabKey studies can integrate QC status and easily filter to identify approved data as well as data that is in need of further attention. You can see a filtered set of data that has not yet been reviewed by clicking here.
Secure Access
Sharing reports and data with collaborators improves research, innovation, and ultimately patient care. Protecting the same information from outside access is vital in maintaining patient privacy. Using a trial server, you can use this tutorial to create a working model to see how role and group based access works.