Biopharma software is an essential tool for managing R&D data of modern biotech organizations. Biologics development is a data-driven endeavor involving many development stages and cross-functional collaboration. The inherent complexity, variety of disciplines producing data, and the sheer volume of data can easily pose a challenge to biopharma research organizations. Many research teams are using general-purpose data management tools (spreadsheets and files) or systems purpose-built for a single data type. This approach can lead to problems in tracking data and duplicating work. This blog post focuses on key considerations when selecting biopharma software for managing R&D data.

Biopharma data management challenges include:
- Integrating data generated from disparate scientific specialties
- Difficulty in finding and highlighting important data (leading to duplication of work)
- Variabilities in data structure and conventions
- Lack of visibility into data provenance
These challenges make it difficult for biopharma researchers to answer some basic scientific questions about their data:
- Do I have the data I need?
- What is this data? (structured data model, definitions)
- Where did this data come from? (data provenance, audit history)
- How and why was it generated? (reproducibility, workflow processes)
Biopharma software can help centralize research data and enforce data standards. This allows for quick and confident answers to the questions scientists ask about their data. Along with data capture, standardizing and monitoring processes is critical to tracking biopharma R&D activity and reducing data inconsistencies.
Biopharma software should include integrated tools for data management.
The LabKey Biologics LIMS provides a central bioregistry with integrated assay data capture, workflow management, and a “data-connected” electronic lab notebook. We consider these to be the pillars of a comprehensive biopharma software solution for data management.
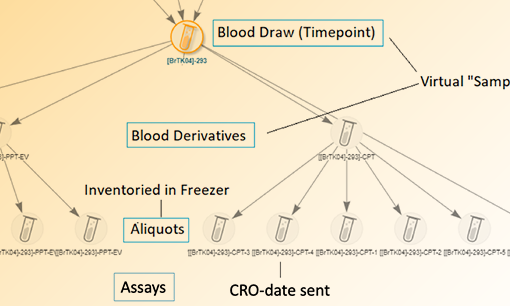
A bioregistry helps scientists define, register, and review interconnected biological entities and their samples. By centralizing biopharma R&D data, researchers can easily find, view, and navigate through entities, their lineage, and data relationships. For example, using a bioregistry, scientists can easily find a specific molecule and see all the related sequences, samples containing it, and related assay data.
Assay data is the decision-making criteria for discovery, process development, and quality. It is generated by all contributing teams and its relevance endures throughout. Having a central, structured, and workflow-related assay data capture mechanism is essential for streamlining decision making, hand-offs, and post hoc analysis. It ensures that consistent data structures are used throughout the biopharma development process, sets expectations for needed data, and makes clear where critical data can be found.
An ELN is designed to help scientists efficiently organize and document their ongoing research. A data-connected ELN provides even more value by having access to the bioregistry, assay, and sample data captured so that additional work is not required to find and include it. This integration paradigm maintains data integrity while enabling easy data exploration and collaboration.
Defining collaborative biopharma workflows helps set expectations for contributors and managers. It supports the fulfillment of material and data needs and prepares the way for process optimization, scheduling, and cross-team alignment. These workflow tools facilitate strategic experimentation, simpler data hand-off, and easier planning.
Biologics LIMS- Biopharma R&D software designed for efficient data management.
Biologics LIMS is a powerful suite of integrated tools to help scientists manage biologics research data, improve lab processes, and collaborate efficiently. The software provides biopharma researchers with streamlined registration and tracking of biological entities and samples in a central bioregistry. The bioregistry is seamlessly integrated with tools for workflow management, assay data management, and an electronic lab notebook (ELN). This combination of software tools forms a cohesive application that serves as a central hub for managing biotherapeutic development data, processes, lab notebooks, and collaboration efforts.
LabKey Biologics helps scientists:
- Speed up decision-making with unified ELN, bioregistry, workflow, and assay data management tools
- Centralize and connect data for a holistic view of your data landscape and interrelationships
- Manage and optimize lab processes with a workflow tool designed for biopharma R&D
Click here to learn more about LabKey Biologics and take a product tour.