Category: About LabKey

Clinical Sample Tracking for Labs and Researchers
Clinical sample tracking helps scientists and research teams know where samples are in the receiving, storage, testing and analysis process. This allows researchers to quickly identify information regarding the patient/study participant, previous assay runs, derivative samples, storage location, history, and more.
When dealing with human-derived samples, tracking the chain of custody and storing sample-related data in a secure environment is vital. Unfortunately, many research groups are still relying on paper trails for clinical sample tracking due to the low cost and familiarity of the approach. These “paper solutions” are highly error-prone, difficult to scale, and difficult to adapt to increasing complexity in the lab. This can greatly reduce productivity, delay execution of a research study, and can pose regulatory compliance risks. For these reasons, selecting a sample management software designed for clinical sample tracking is critical for success.
When looking for a clinical sample tracking system, consider the following:
- Is clinical sample data being stored securely with the proper safeguards to ensure regulatory compliance?
LabKey Sample Manager offers CFR Part 11, HIPAA and FISMA compliant software and hosting, used by leading life science organizations and the FDA. This includes built-in methods to restrict PHI/PII data access, and e-Signing data, managing sensitive data in a secure way is easy and transparent. - Is the sample’s chain of custody captured in the system and easy to retrieve?
Not only does Sample Manager create audit-ready logs for all sample events, we have a unique Sample Timeline that allows users to easily browse a sample-centric chain of custody for auditing and troubleshooting. - Can you customize fields and add built-in validation to ensure correct data entry?
Sample Manager allows administrators to add validators to both numeric and text fields to ensure correct data entry. Quality Control tools allow assay data to be reviewed before it’s shared to ensure that only relevant data is displayed to teams. - Can the clinical sample tracking system provide built-in reporting capabilities that create custom reports unique to your lab’s needs?
LabKey has built-in reporting and charting tools to quickly assess the data, as well as many advanced tools such as built in R and SQL reporting, integrations with Tableau, Spotfire, etc. - Can I capture participant clinical data within the same tool to centralize my data?
LabKey has an extensive study module that integrates with our clinical sample tracking system that allows teams to capture all clinical data. We integrate with REDCap and Medidata RAVE as well. Our study publishing capabilities allow teams to share information with collaborators in a secure way including date-shifted and de-identified data.
Want to learn more about our clinical sample tracking solutions?
>LabKey Sample Manager – product overview and tour
>Request a Demo
Essential Software Considerations for Tracking Biological Samples
Getting Started with Lab Inventory Tracking

What’s New in LabKey 23.7

Specimen Tracking for Biobanks
5 Benefits of Using an Electronic Lab Notebook
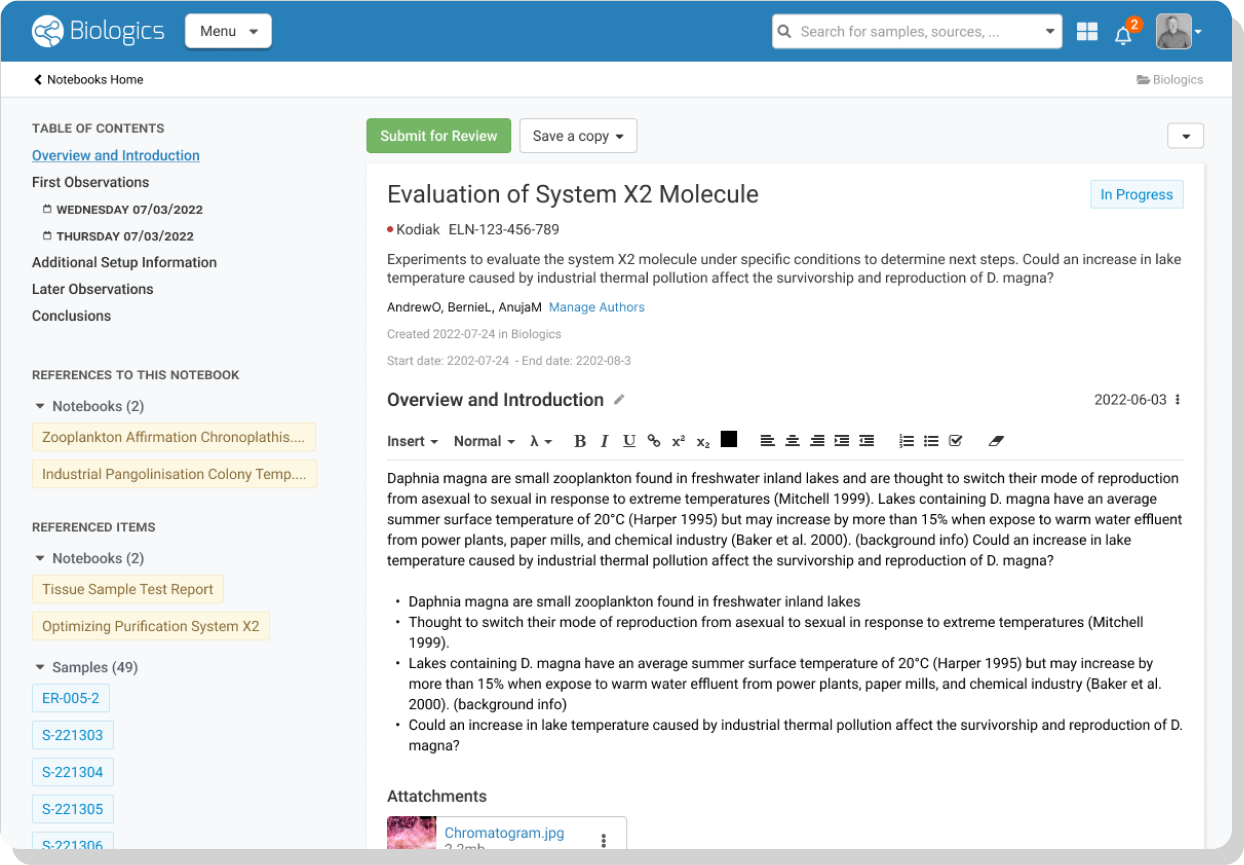
The biologics development process is a data-driven endeavor. A vast amount of data is generated from many teams with the hopes of answering questions and informing decision-making along the way. Centralizing this data and their analyses across experiments amplifies the power and impact that data has on biologics research and development.
Of course, centralizing biologics assay data means much more than simply storing data in the same place. Data centralization increases the value of biologics data beyond one particular experiment or result by defining data relationships. The ability to aggregate data across multiple samples, assays, and experiments, with metadata describing the relationship of all of these to each other, is where modern data science resides. Whereas the analysis of a single value from a single assay shows a distribution, joining that assay with others reveals a richer data landscape that is ripe for analysis. These data landscapes yield even more insights when they are related to one another across many controlled variables and conditions.
Below are more ways that implementing tools and strategies for data centralization can impact the speed and efficiency of biotherapeutic development.
Data Integrity
Having a single source of truth for data makes it easier for organizations to track how (and by whom) data is generated, accessed, and modified. With the assistance of a biologics data management application serving as a central hub- permissions, auditing, and backups provide control over how, when, where, and by whom data is used. Centralization of data also encourages standardization of data formats across research teams. Standardizing data structures helps validate the data being entered and helps preserve the relationships between data. This leads to downstream efficiency and maximizes the utility of experiments beyond the individual or team from which it was derived.
Collaboration
Centralizing biologics research data also helps promote collaboration between research teams. By storing data in one central location in standardized formats, scientists can easily find, compare and reference existing data in their research. A central repository for data also makes it much easier to see what data is missing or needed to inform decisions. Hand-offs of data are also made easier when all data is centrally stored.
About our Biologics LIMS
LabKey Biologics provides researchers with a set of tools to centralize biological entity registration, workflow management, and data exploration.
- Bioregistry – Register and track molecular entities, nucleotide sequences, protein sequences, expression systems, constructs, vectors, and cell lines
- Biologics Assay Management – Connect design data to related multi-dimensional assay results for a complete data landscape.
- Biologics Workflow Manager – Centrally manage biologics development workflows to help your team collaborate
- Electronic Lab Notebook – Highlight and connect your research entities and data with our biologics ELN
Click Here to take a tour of LabKey Biologics.
What’s New in LabKey 23.3

NIH Data Management & Sharing Policy

The biologics development process is a data-driven endeavor. A vast amount of data is generated from many teams with the hopes of answering questions and informing decision-making along the way. Centralizing this data and their analyses across experiments amplifies the power and impact that data has on biologics research and development.
Of course, centralizing biologics assay data means much more than simply storing data in the same place. Data centralization increases the value of biologics data beyond one particular experiment or result by defining data relationships. The ability to aggregate data across multiple samples, assays, and experiments, with metadata describing the relationship of all of these to each other, is where modern data science resides. Whereas the analysis of a single value from a single assay shows a distribution, joining that assay with others reveals a richer data landscape that is ripe for analysis. These data landscapes yield even more insights when they are related to one another across many controlled variables and conditions.
Below are more ways that implementing tools and strategies for data centralization can impact the speed and efficiency of biotherapeutic development.
Data Integrity
Having a single source of truth for data makes it easier for organizations to track how (and by whom) data is generated, accessed, and modified. With the assistance of a biologics data management application serving as a central hub- permissions, auditing, and backups provide control over how, when, where, and by whom data is used. Centralization of data also encourages standardization of data formats across research teams. Standardizing data structures helps validate the data being entered and helps preserve the relationships between data. This leads to downstream efficiency and maximizes the utility of experiments beyond the individual or team from which it was derived.
Collaboration
Centralizing biologics research data also helps promote collaboration between research teams. By storing data in one central location in standardized formats, scientists can easily find, compare and reference existing data in their research. A central repository for data also makes it much easier to see what data is missing or needed to inform decisions. Hand-offs of data are also made easier when all data is centrally stored.
About our Biologics LIMS
LabKey Biologics provides researchers with a set of tools to centralize biological entity registration, workflow management, and data exploration.
- Bioregistry – Register and track molecular entities, nucleotide sequences, protein sequences, expression systems, constructs, vectors, and cell lines
- Biologics Assay Management – Connect design data to related multi-dimensional assay results for a complete data landscape.
- Biologics Workflow Manager – Centrally manage biologics development workflows to help your team collaborate
- Electronic Lab Notebook – Highlight and connect your research entities and data with our biologics ELN
Click Here to take a tour of LabKey Biologics.
